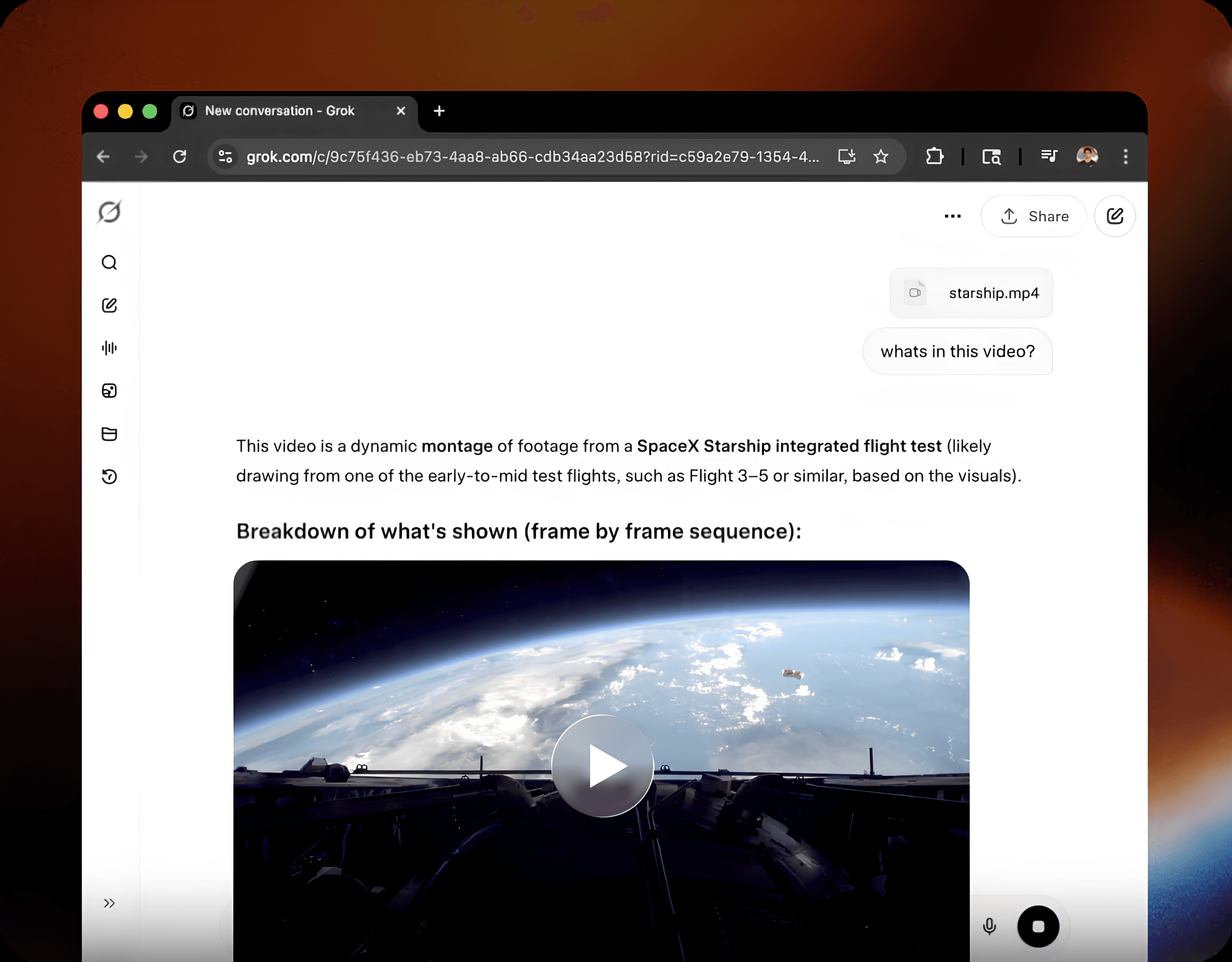
Grok 4.3: Built for Long Documents and Agentic Work
xAI’s Grok 4.3 brings always-on reasoning, native video understanding, and a 1M token context window built for long-horizon agentic work and enterprise-scale deployment.
Trusted by users from 10,000+ companies
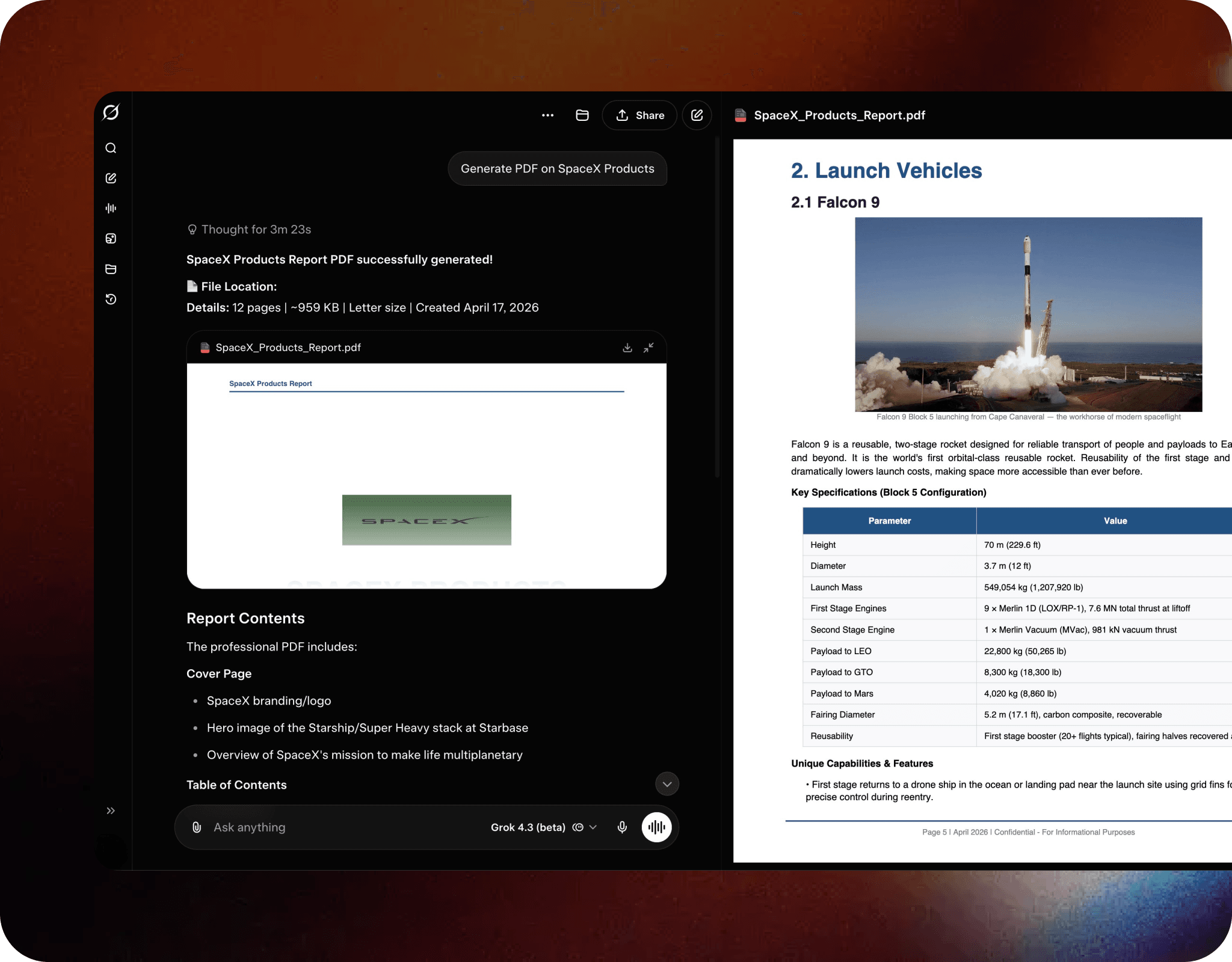
Additional Capabilities in Grok 4.3 A broader set of improvements that extend Grok 4.3's usefulness across development, research, and enterprise workflows.

Reasoning is active by default on every request and cannot be disabled, ensuring consistent depth on complex and ambiguous tasks without configuration.
Ships with a built-in environment that can write, run, and produce files, enabling end-to-end code workflows without external tooling.

A new client-side agent library gives developers structured access to Grok 4.3's agentic capabilities for building and deploying custom workflows.
Discover more about Grok 4.3 through common user queries online.
Custom Voices, xAI's new voice cloning suite, is available alongside Grok 4.3, priced at $4.20 per million characters with natural prosody controls.
Now generally available with transcription across 25 languages, batch and streaming modes, and multi-speaker diarisation with word-level speaker IDs.
The same voice stack powering Grok Voice and Tesla vehicles is now accessible via API, with inline speech tags for prosody control at scale.

Requests up to 200K tokens are billed at standard rates. Beyond that, a higher tier applies, giving teams control over cost based on actual context usage.

Grok 4.3 is fully accessible via OpenRouter and compatible with the OpenAI SDK, making it a low-friction drop-in for existing API integrations.
Tighter integration with Grok Computer which enables Grok 4.3 to take direct action on software tasks beyond the chat interface.
Grok 4.3 sits on the Pareto frontier for intelligence versus cost, scoring higher while costing less to run than its predecessor.

Grok 4.3 scores an ELO of 1500 on GDPval-AA, a 321-point jump over its predecessor. It’s ahead of multiple frontier models on the benchmark designed to measure performance on economically valuable knowledge tasks.
Despite scoring higher on the Artificial Analysis Intelligence Index, Grok 4.3 costs around 20% less to run the full benchmark suite than Grok 4.20. More capable and cheaper to operate among top-performing competitor models.

Grok 4.3 gains 8 points on AA-Omniscience Accuracy over Grok 4.20, reflecting a measurable improvement in factual retrieval across knowledge-intensive tasks. For legal research, technical analysis, scientific reasoning.




With a 1 million token context window and no output token limit, Grok 4.3 can take in entire legal case histories, financial filings, research libraries, or large codebases in a single session.