Claude Opus 4.7 – A Serious Model for Curious Workers
Claude Opus 4.7 handles your hardest, longest work from end to end, without hand-holding. Try it now and see what an actually smart model feels like.
Trusted by users from 10,000+ companies
Across every type of knowledge work, Opus 4.7 raises the bar in ways that add up fast.
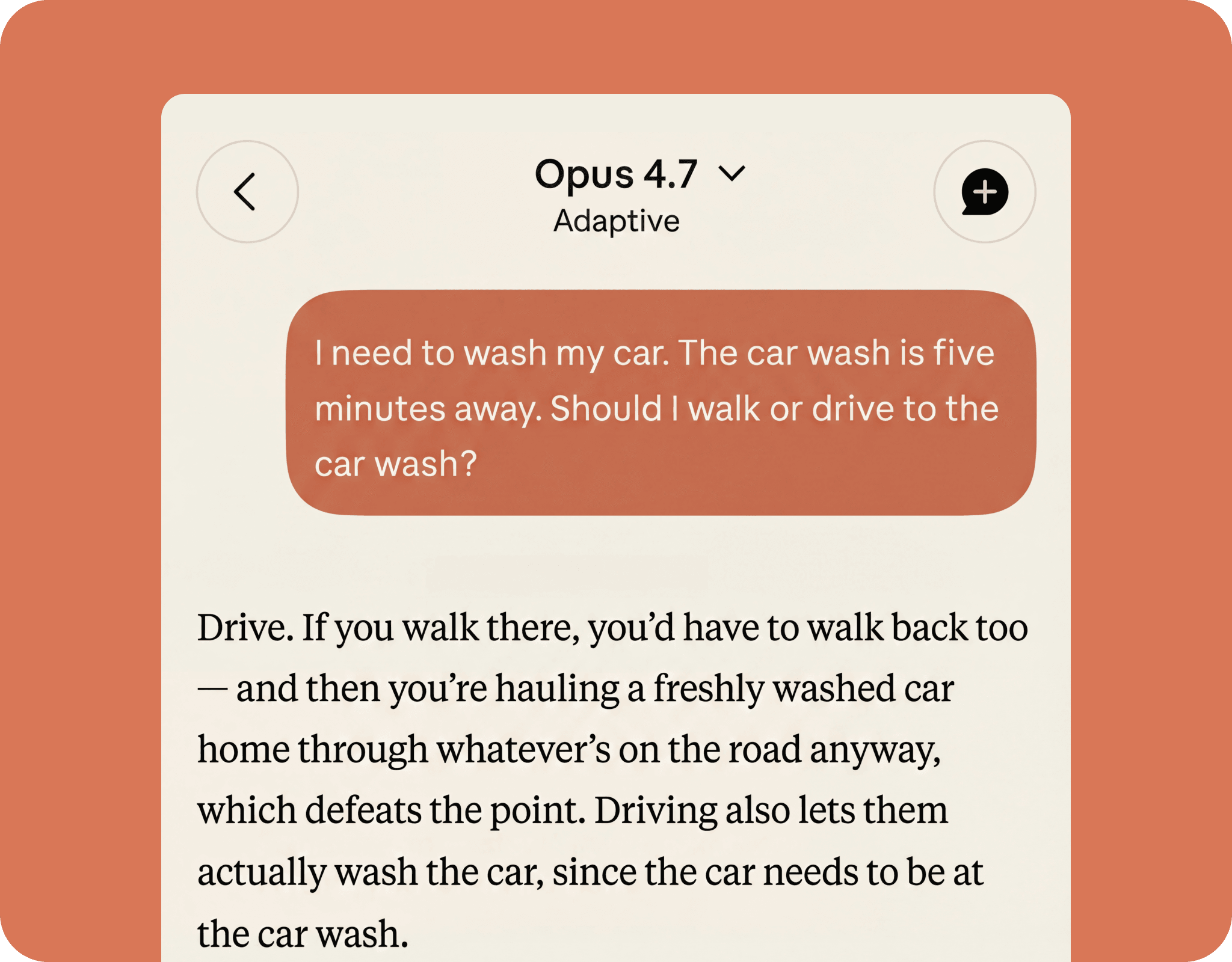
Follows your instructions exactly as written. No silent assumptions, no unrequested additions, no guessing what you probably meant.
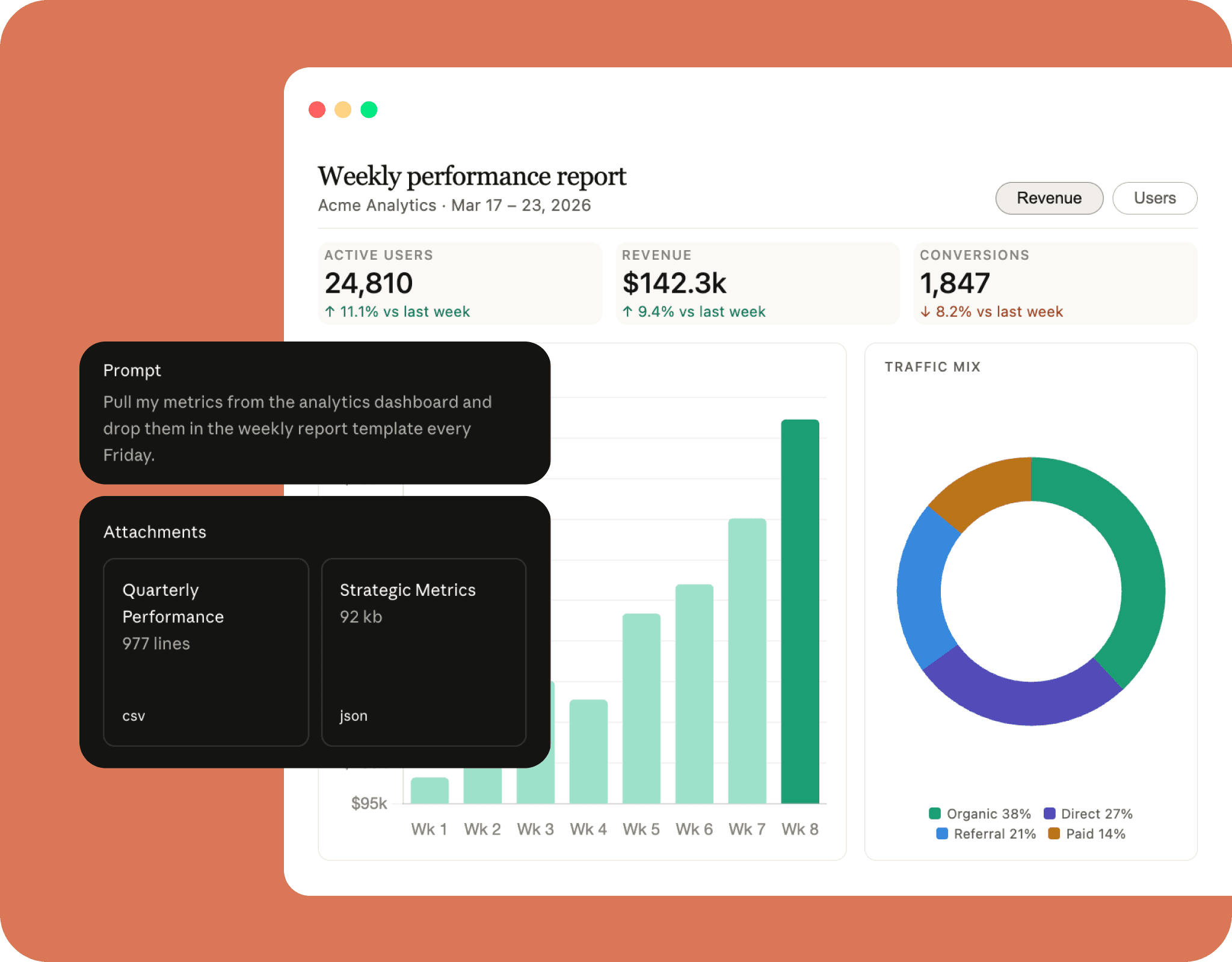
Holds up to one million tokens of context in a single session. Enough for entire codebases, full contracts, or months of research.
A new xhigh effort setting lets you dial up reasoning on the hardest problems without committing to max compute on every task.
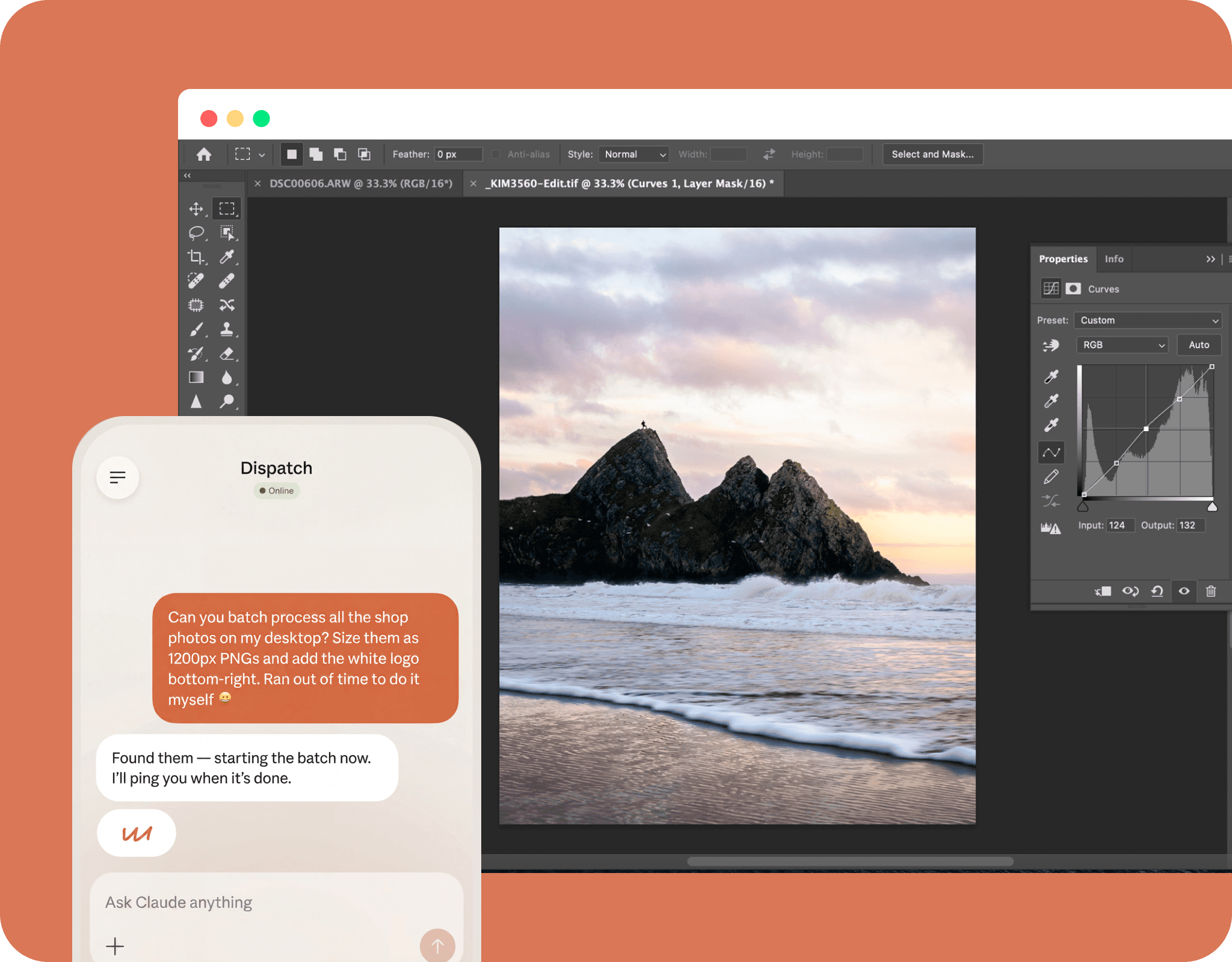
There is much more to discover about Claude Opus 4.7. Start by reading some of the user inquiries.
Give the model a token budget for a full task and it will scope its work accordingly. Useful when cost and runtime both matter.
Produces and self-reviews presentation layouts before returning them, catching visual errors that would otherwise need a manual pass.

When data is missing or a question can't be answered with confidence, Opus 4.7 says so. It does not fill gaps with plausible-sounding guesses.

Generates tracked changes in Word documents with improved accuracy, handling complex edits and checking its own output against the original.
On long tasks, Opus 4.7 proactively signals where it is in the work. So you always know what's happening without having to ask.
Stronger defences against attempts to hijack the model's behaviour through malicious content embedded in documents or external data.
Opus 4.7 leads across the evaluations that track what professionals actually do at work.

Opus 4.7 ranks first on benchmarks across finance, legal, and business analysis. Meaning it produces the accurate output that industry professionals can trust, not output that looks correct at a glance.

In legal document review, getting the substance right matters more than getting it fast. Opus 4.7 scores 90.9% on BigLaw Bench and correctly handles the contract distinctions that routinely trip up less capable models.
Across enterprise document workflows like reading, reasoning, and extracting from source material, Opus 4.7 makes 21% fewer errors than Opus 4.6, which means fewer corrections and less back-and-forth.




Opus 4.7 checks its own work as it goes. It spots mistakes in its own plans before you do, and corrects them without being asked. You can assign a multi-step project and come back to a finished result.