GPT-5.5: Smarter decisions, Less guidance required
GPT- 5.5 is OpenAI's most capable model designed for complex, real-world work. It figures out what needs to happen next, uses tools to get there, and checks its own work along the way.
Trusted by users from 10,000+ companies
Apart from headline changes, GPT-5.5 offers smaller improvements that compound into bigger advantages.
GPT-5.5 completes the same tasks using significantly fewer tokens than GPT-5.4, delivering more capable results at lower cost in Codex.
Despite the jump in capability, GPT-5.5 matches GPT-5.4's per-token latency in real-world serving. More intelligence, no wait penalty.
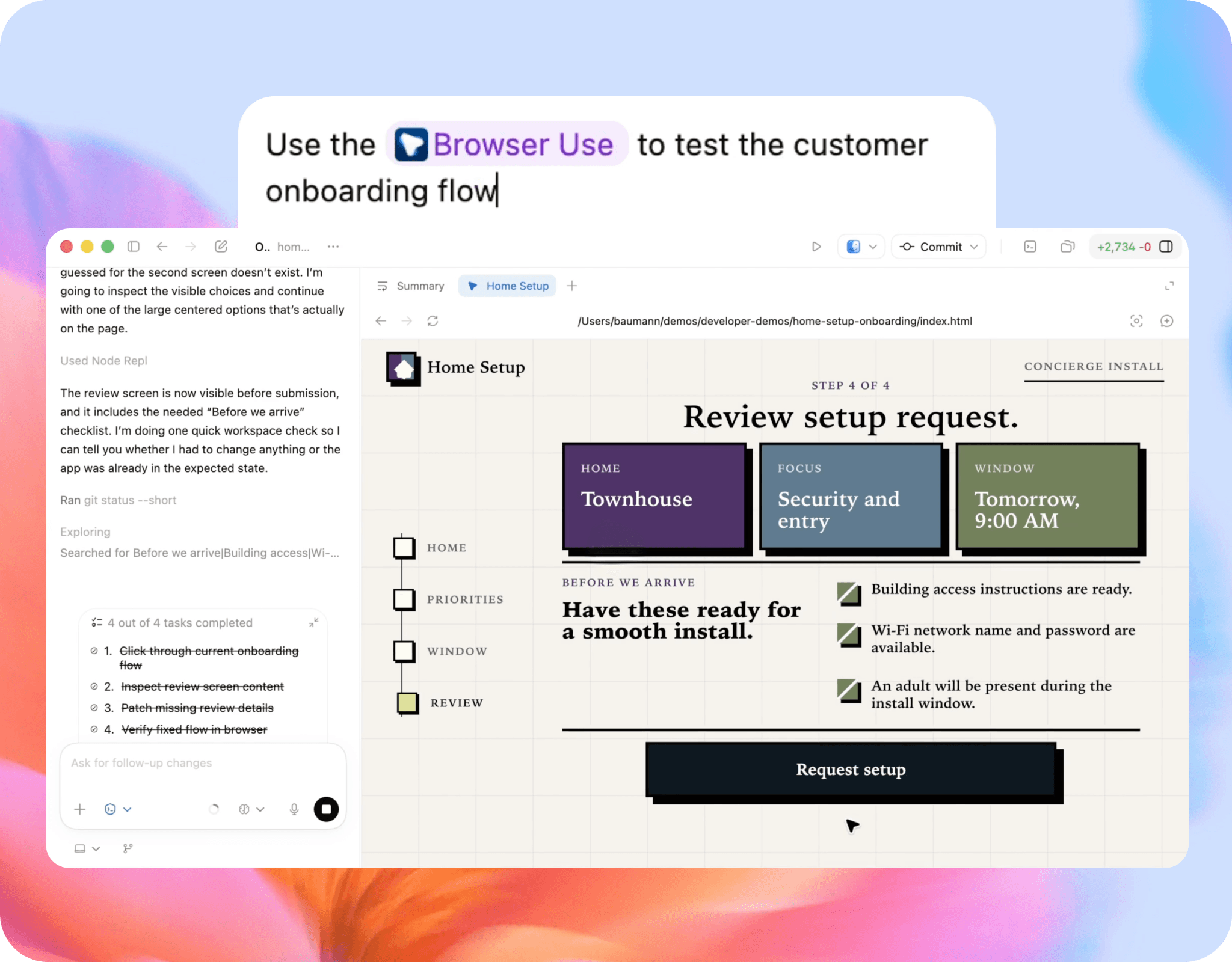
GPT-5.5 can operate software directly, navigating interfaces, filling forms, and executing multi-step tasks the way a person would.
Quick answers covering access, pricing, capabilities, and how GPT-5.5 compares to previous models.
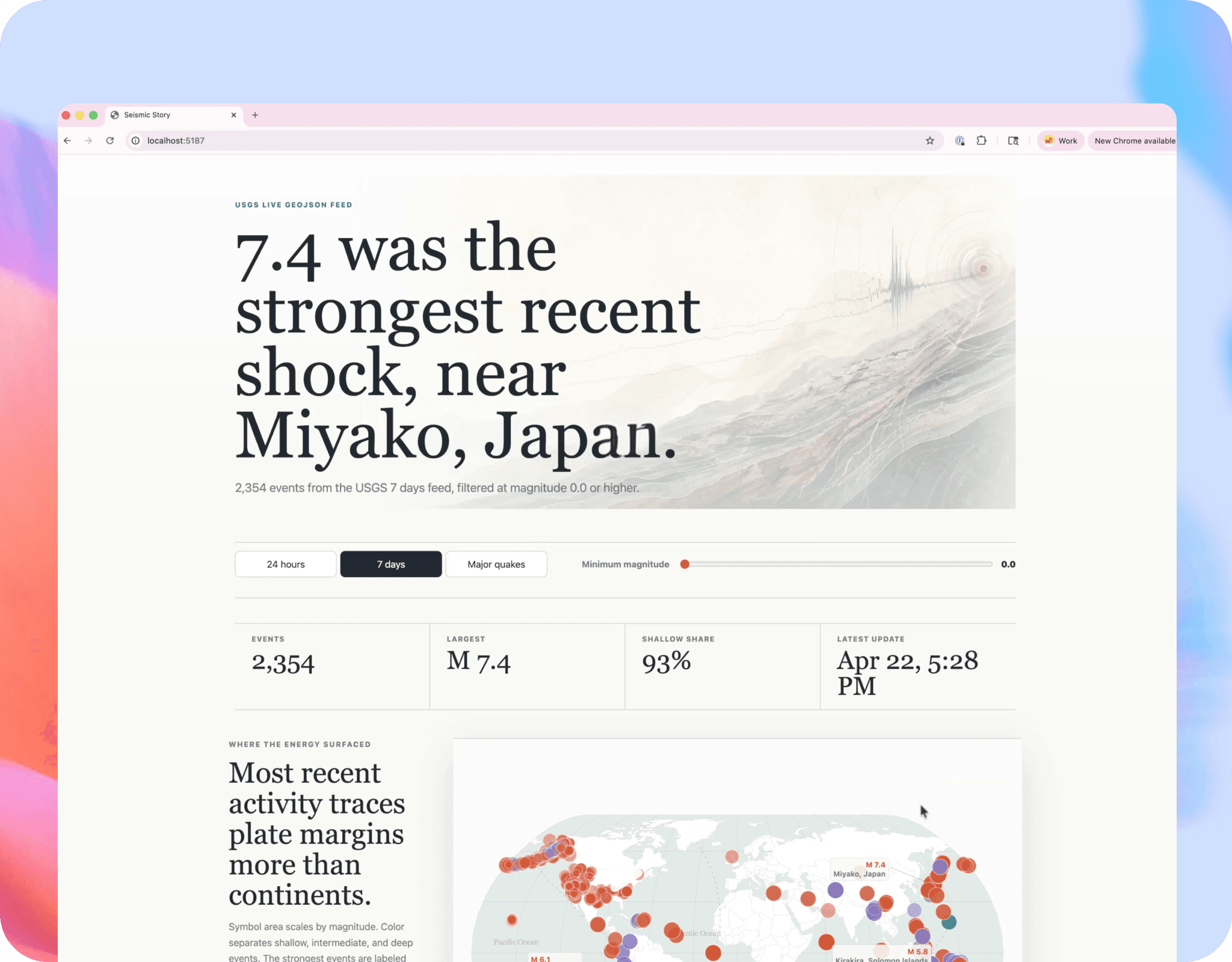
Meaningful gains on scientific and technical research workflows, including early-stage drug discovery and experimental debugging tasks.

GPT-5.5 distinguishes its own work from user work and reverts only its own changes, protecting user output even in complex, multi-agent environments.

Holds context reliably across large systems and long sessions, carrying changes through surrounding codebases without losing track of earlier decisions.
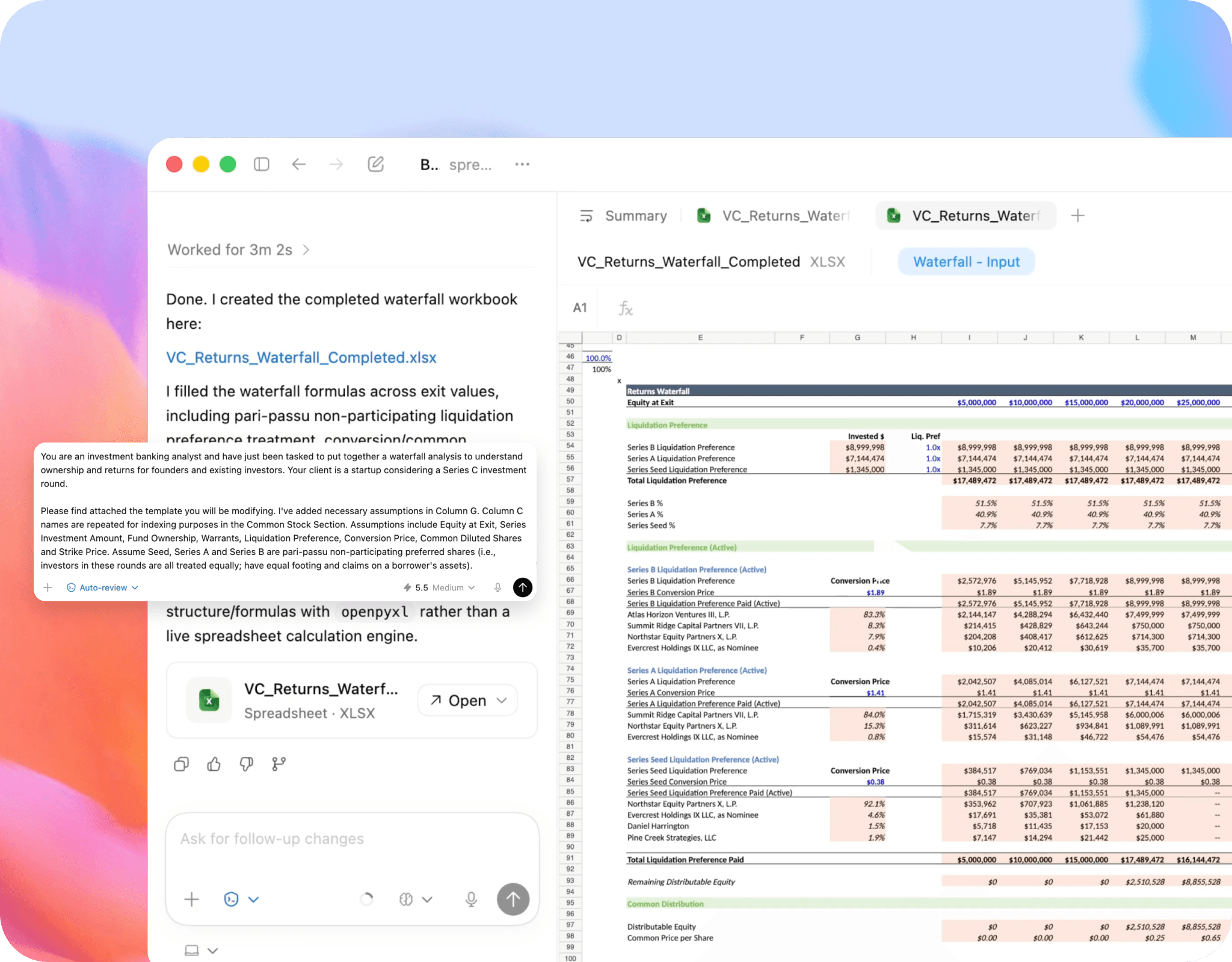
Improved latency on document and spreadsheet creation tasks, producing complete, structured outputs faster without sacrificing accuracy.
Verified defenders can apply for Trusted Access for Cyber to unlock GPT-5.5's advanced security capabilities with fewer restrictions for legitimate defensive work.
GPT-5.5 is the default model in Codex for all paid tiers, with OpenAI's tuning specifically optimised for agentic coding performance at lower token cost.
GPT-5.5 leads across the evaluations that mirror how professionals and researchers actually work.
GPT-5.5 scores higher than any previous GPT model on HealthBench Professional,designed for clinical use cases, with both higher raw and length-adjusted scores.

GPT-5.5 leads SWE-Bench Verified, placing it at the top of the field for resolving real production software issues autonomously across full codebases.

On conversations where users had previously flagged factual errors, GPT-5.5's individual claims are 23% more likely to be correct, improving precision and trustworthiness.




GPT-5.5 understands what a task actually requires before starting, identifies the gaps in ambiguous briefs, and builds a plan without waiting to be walked through it. Early access teams reported saving up to 10 hours of work per week.