Experience Gemini 2.5 Flash for Lightning-fast Reasoning
Gemini 2.5 Flash is the next-generation AI model by Google DeepMind, engineered for production workflows that demand speed, affordability, and advanced reasoning.
Trusted by users from 10,000+ companies
Gemini 2.5 Flash handles rich, mixed inputs to elevate reasoning quality with coherence and control.
Delivers expressive, real‑time voice interaction with tone, accent, and prosody control for richer conversational experiences.
Detects user voice emotion and ambient signals and then adapts its replies accordingly for more natural engagement.

Enables steering of voice output by letting you choose tone, accent, or whisper mode to align with context or brand voice.
Learn more about Gemini 2.5 Flash through these common queries.

In addition to reasoning, it supports seamlessly creating and editing images using simple text + image prompts.
Capable of coordinating multiple tool calls and search integrations during a session for enriched, dynamic workflows.
Achieves 20‑30% fewer tokens in evaluations compared to previous versions, reducing overhead for large input‑output tasks.
Accepts and interprets a mix of text, images, audio, and video inputs in one unified workflow for richer data fusion.
Provides introspective summaries of its reasoning process (tool usage, steps taken) so developers and users can follow logic.

The model dynamically adjusts how much "thinking" it does, based on task complexity, when no manual budget is set.
Gemini 2.5 Flash turns high-volume, real-time experiences into smooth, scalable reality.

Independent analysis found that Gemini 2.5 Flash and Flash-lite achieved throughput of ~887 output tokens per second, a 40% speed improvement over the prior version, which proves that Flash is built with high‑throughput scenarios in mind.
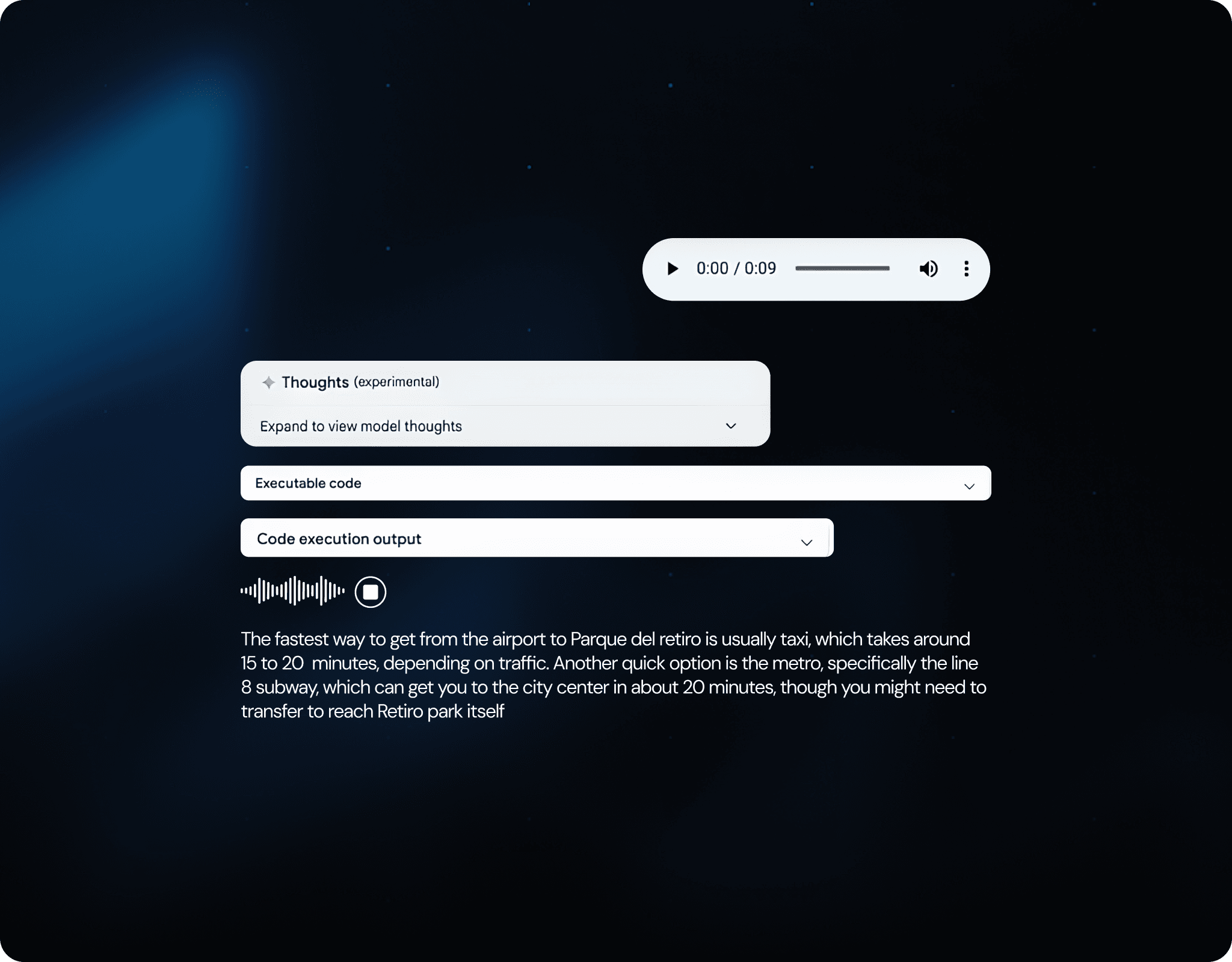
The model introduces native “thinking” features, meaning you can toggle how much reasoning budget it uses, invoke tool‑calls, function‑calling, code execution, and grounding with search.

The model supports inputs across text, image, video, audio, and PDF. It also integrates capabilities like function‑calling and search‑grounding, which enable more dynamic and real‑world workflows, going beyond pure text.



Bring teams together around insights that emerge from mixed data streams and conversational workflows. Gemini 2.5 Flash enables shared understanding by synthesising input from multiple formats and producing structured, easy‑to‑review outputs.