Meet Grok 3 Mini: Model Built for Everyday Intelligence
Grok 3 Mini is a compact model from xAI that brings advanced reasoning power and lightning-fast performance.
Trusted by users from 10,000+ companies
Dive into the features that elevate this model beyond just speed or reasoning depth.
You can inspect the chain-of-thought behind each answer, giving visibility into how the model arrived at its conclusion and enhancing trust in the process.
It allows the invocation of external tools or APIs, enabling seamless interaction between the model and your applications or services.
Trained on a broad array of scientific, mathematical, and logical datasets, it brings informed responses across diverse subjects.
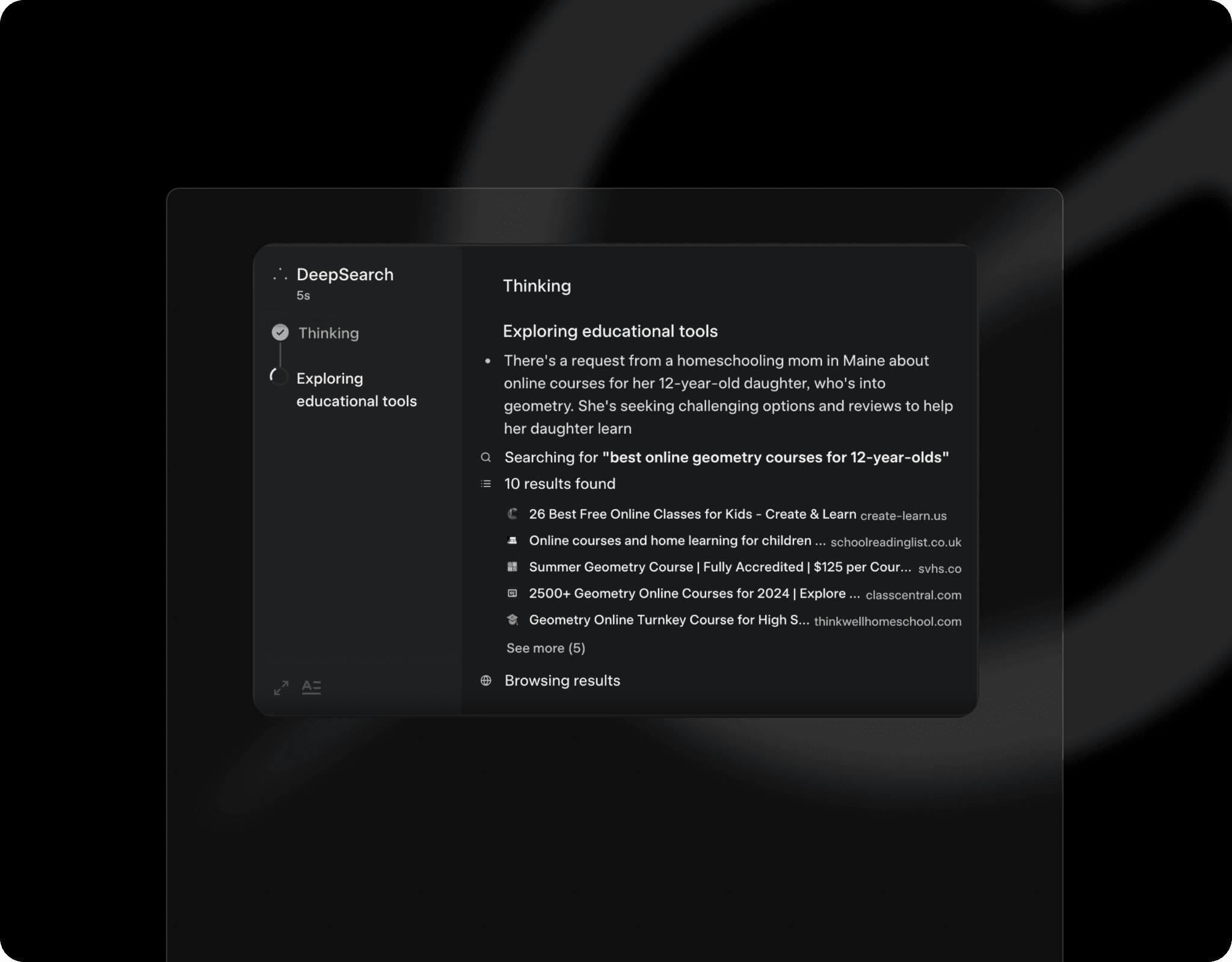
Find what queries people have been making online.

The model responds well to subtle cues, instructions, and context shifts, making your interactions more natural and effective.
With support for multiple SDKs and API formats, it fits comfortably into your existing tech stack or workflow.

Capable of processing very large context windows, it maintains coherence even when dealing with extended inputs or multi-part tasks.
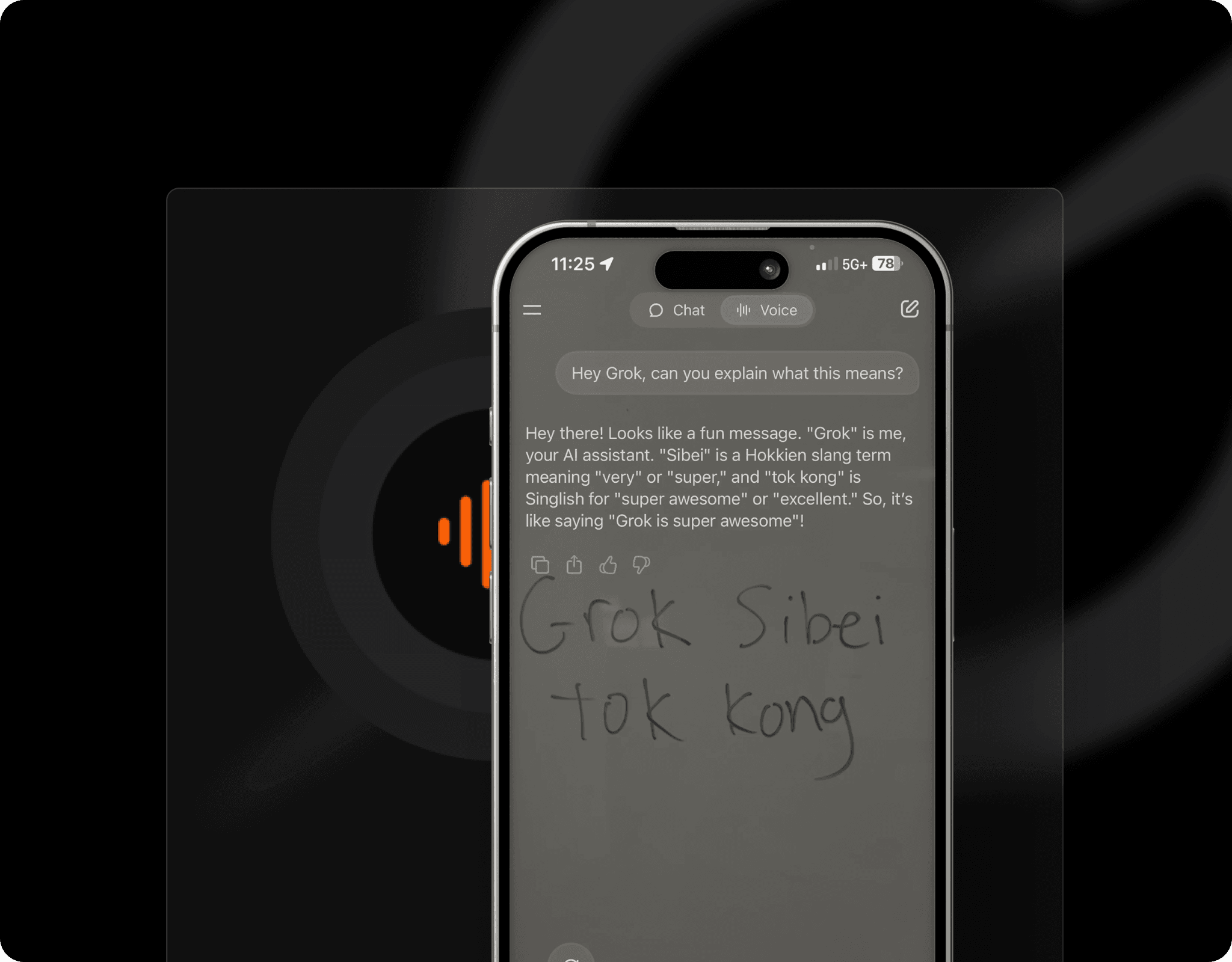
It delivers reliable performance in a wide range of languages, so you’re not limited to English-only use.

Designed for quick responses, it keeps conversational flow intact and feels responsive even in rapid-exchange settings.
Built to integrate into workflows and evolve with your needs, it supports varied deployment scenarios from simple to complex.
Grok 3 mini delivers fast responses, dependable quality, and a friendly cost profile.
Grok 3 Mini shows its internal reasoning traces, allowing users to inspect how the model arrived at an answer rather than just what the answer is. This transparency improves trust and auditability in cases where understanding the logic matters.

Grok 3 Mini supports a context window of up to 131,072 tokens, enabling it to ingest and maintain coherence across very large inputs. This means it can handle workflows that span many pages of text, long chat histories, or multi-file development contexts.

This model is explicitly optimized for environments where speed, cost, and deployment scale matter. For example, the pricing structure lists input tokens at approximately $0.30 per million and output tokens at $0.50 per million in many regions.




Unlock high-level reasoning and clarity without the weight of constant manual thinking. With intelligent structure and deep understanding, the model supports your mental flow in and around work, study, or creative sessions.