Explore DeepSeek R1: Faster and Efficient Next-Gen Reasoning Model
DeepSeek R1 empowers developers, enterprises and researchers with high-performance logic, math, and code abilities at lower cost.
Trusted by users from 10,000+ companies
Deepseek R1 packs a suite of advanced capabilities that elevate performance, accessibility, and flexibility for a wide range of users.
Activates only a subset of its 671 billion parameters (~37 billion) per pass, making inference far more compute-efficient.

Supports context lengths up to 128k tokens, enabling sustained reasoning across long documents or multi-turn dialogues.

Uses latent vector compression to drastically reduce memory usage in attention layers, enhancing scalability and speed.
Find out the answer to the most common questions people are asking.
Predicts multiple future tokens in parallel instead of one at a time, boosting throughput especially in long-form generation.
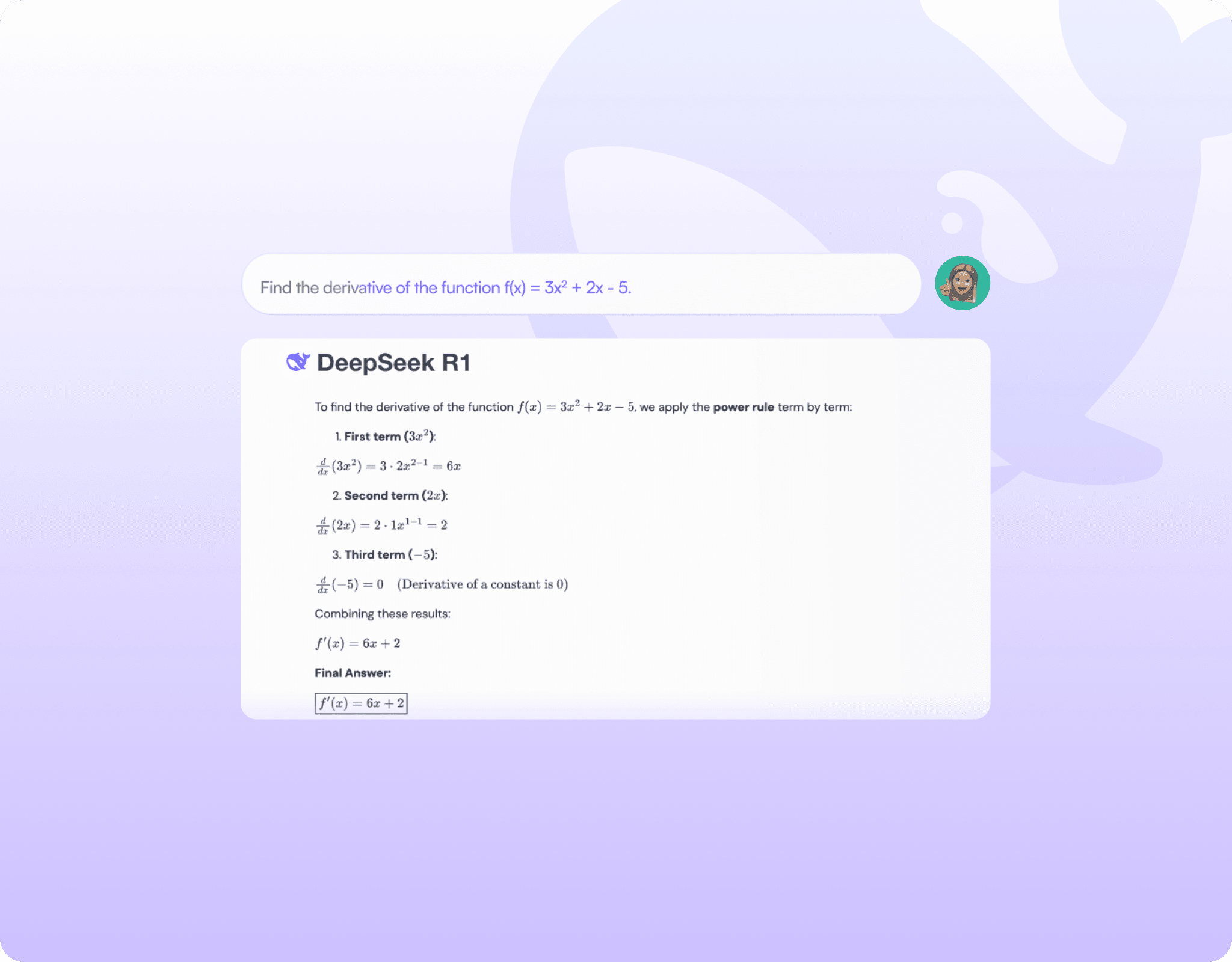
Built via RL and chain-of-thought techniques, equipping the model with advanced reasoning and step-by-step problem solving.

Released under permissive licensing with smaller, efficient versions for diverse hardware and use cases.
Demonstrates strong performance across languages and domains (math, code, logic), not just vanilla language tasks.
Its architecture and inference optimisations allow for significant cost savings compared with many peer models, thanks to Deepseek R1’s pricing.
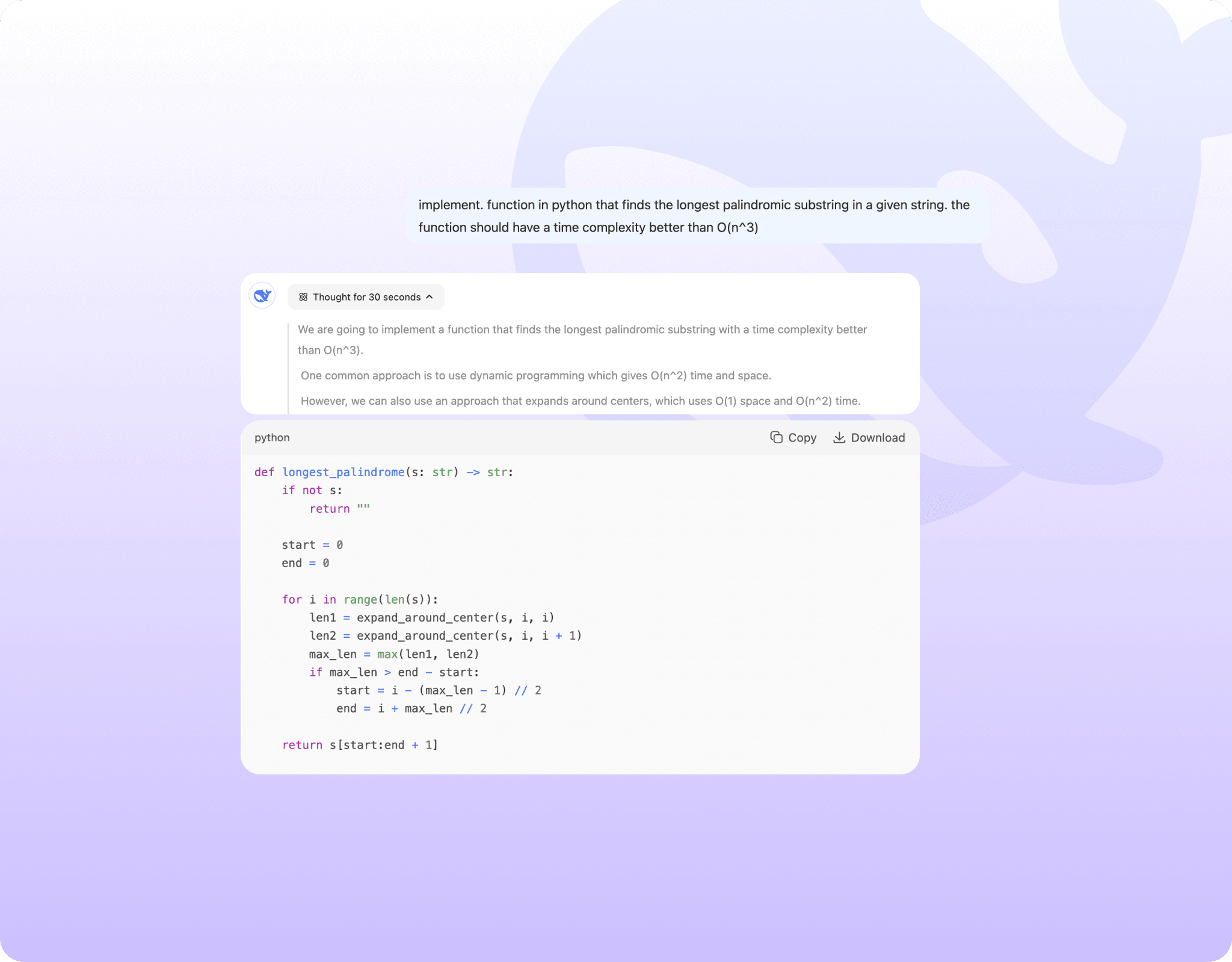
Designed for tool-calling, long-context workflows and seamless integration via Deepseek R1 API, supporting modern production environments.
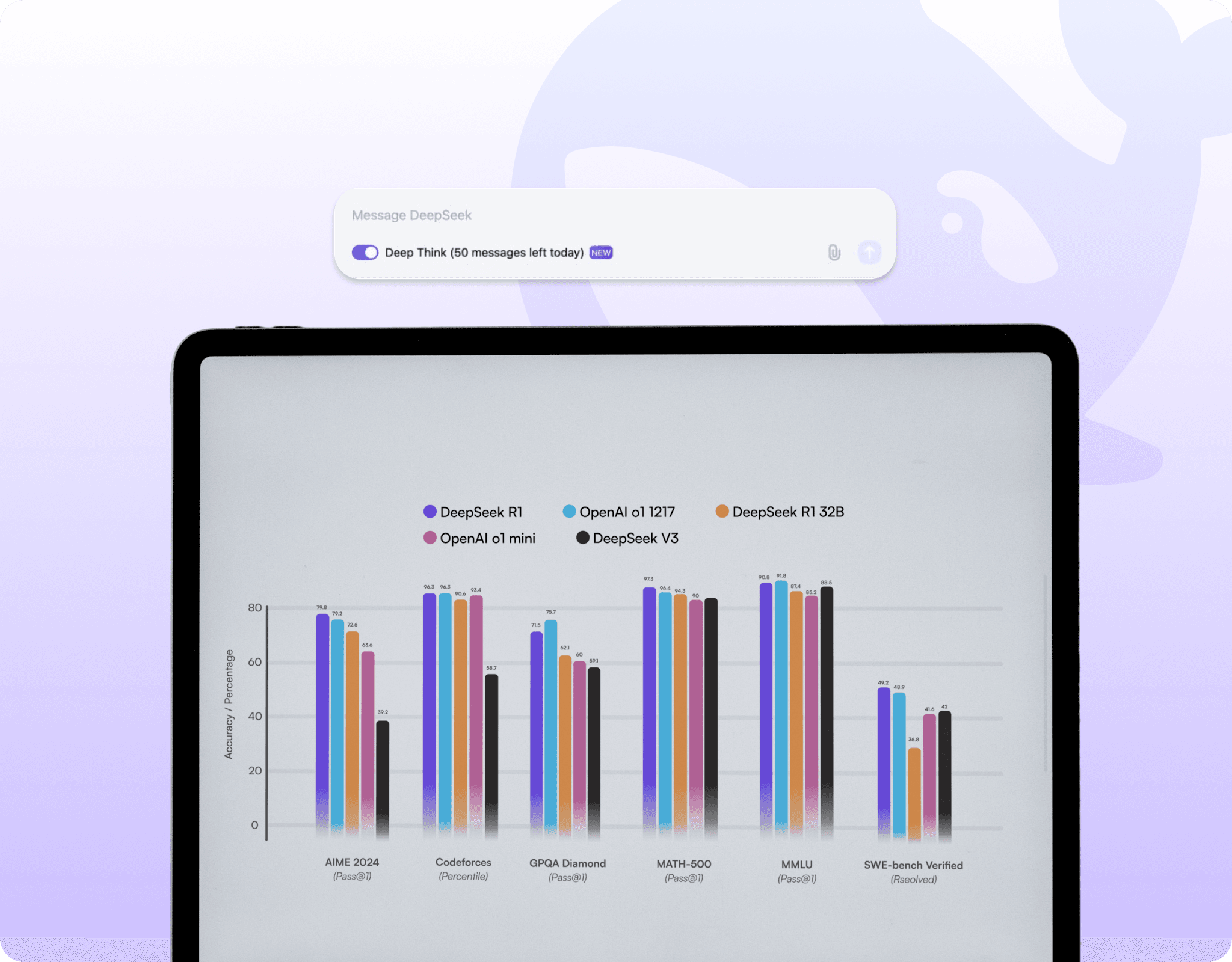
DeepSeek R1 delivers exceptional reasoning and competes with other top models on most of the benchmarks but at more accessible cost.

DeepSeek R1 achieves a Codeforces percentile of ~ 96.3 % in coding and algorithmic reasoning tasks, placing it nearly on par with top proprietary models. It also reports a MATH-500 score (~ 97.3 %) on math reasoning benchmarks.

DeepSeek R1 supports a context length of up to 128 k tokens in preview mode, enabling the model to process very large documents, multi-turn dialogues or complex reasoning chains without losing context.
Deepseek R1 is on GitHub as an open-source model and is accessible via API/enterprise platforms. It gives developers more flexibility and outperforms competitors in public benchmarks, making it a compelling value choice.



Tap into deep thinking and let the model surface connections you may not have considered. With DeepSeek R1 you get sustained reasoning over large inputs, helping you explore ideas thoroughly rather than just scratch the surface.